Why Do LLMs Get Lost in Multi-Turn Conversation?
2026/06/22 · Runqing Xu
对话是 LLM 的第一界面
从 2022 年 ChatGPT 发布至今,对话式 AI 已发展为覆盖数十亿用户的基础设施。
2026.06
用户的真实使用模式
据 LMSYS-Chat-1M、WildChat
编程、客服、咨询等
编码助手、复杂规划
核心观察 — 对话是用户表达需求、迭代想法、协作完成任务的基本方式。然而学术评测几乎全在单轮设定下进行。
评测的断层
学术 benchmark 几乎全部是 single-turn, fully-specified 设定。
| Benchmark | 领域 | 设定 | 状态 |
|---|---|---|---|
| MMLU / MMLU-Pro | 知识推理 | 单轮 | 已饱和 (>90%) |
| HumanEval | 代码生成 | 单轮 | 已饱和 |
| GSM8K | 数学推理 | 单轮 | 已饱和 (~99%) |
| GPQA-Diamond | 科学推理 | 单轮 | 活跃 |
| SWE-Bench Verified | 软件工程 | 单轮 | 活跃 |
| MT-Bench | 多轮对话 | 2 轮 / Episodic | 已饱和 |
两种 “多轮” 的本质区别
每轮是独立子任务,可单独评测。
例:“写个故事” → “改成第一人称”
本质上是多个单轮的串联。每轮指令完整指定。
信息跨轮逐步披露,需跨轮融合。
例:“写个函数” → “处理 JSON” → “这几个字段”
新信息可能推翻早期假设。每轮指令不完整。
Herlihy et al. (UAI 2024) — 真实人机对话中 underspecification 极为普遍。然而现有多轮 benchmark 几乎全采用 episodic 设定,系统性地高估了 LLM 的多轮能力。
多轮对话的四个结构性挑战
“When LLMs take a wrong turn, they get lost and do not recover.”
上下文管理:现有范式
| 方法类别 | 核心思路 | 代表工作 | 优化目标 |
|---|---|---|---|
| 扩展窗口 | 更长的 context window | Gemini 2M, Llama 4 Scout | 容量 |
| 压缩 / 摘要 | 压缩为更短表示 | Auto-compact, Mt-osc | 效率 |
| 外部存储 | 存入外部 memory | MemGPT, RAG | 容量 + 检索 |
| 剪枝 / 截断 | 移除不重要的 token | LLMLingua, Provence | 效率 |
这些方法共享同一个优化方向:如何在有限窗口中装下更多有用信息。但它们没有回答另一个问题 — 上下文中已有的信息,是否都还值得保留?
被取代的旧方案、已完成任务的中间过程、被否决的探索路径 — 这些内容不仅占用空间,更可能主动干扰模型对当前任务的推理。这不是“空间不够”的问题,而是上下文质量的问题。
本次分享路线图
LLMs Get Lost in Multi-Turn Conversation
Philippe Laban* · Hiroaki Hayashi*
Yingbo Zhou* · Jennifer Neville
Microsoft Research & Salesforce Research
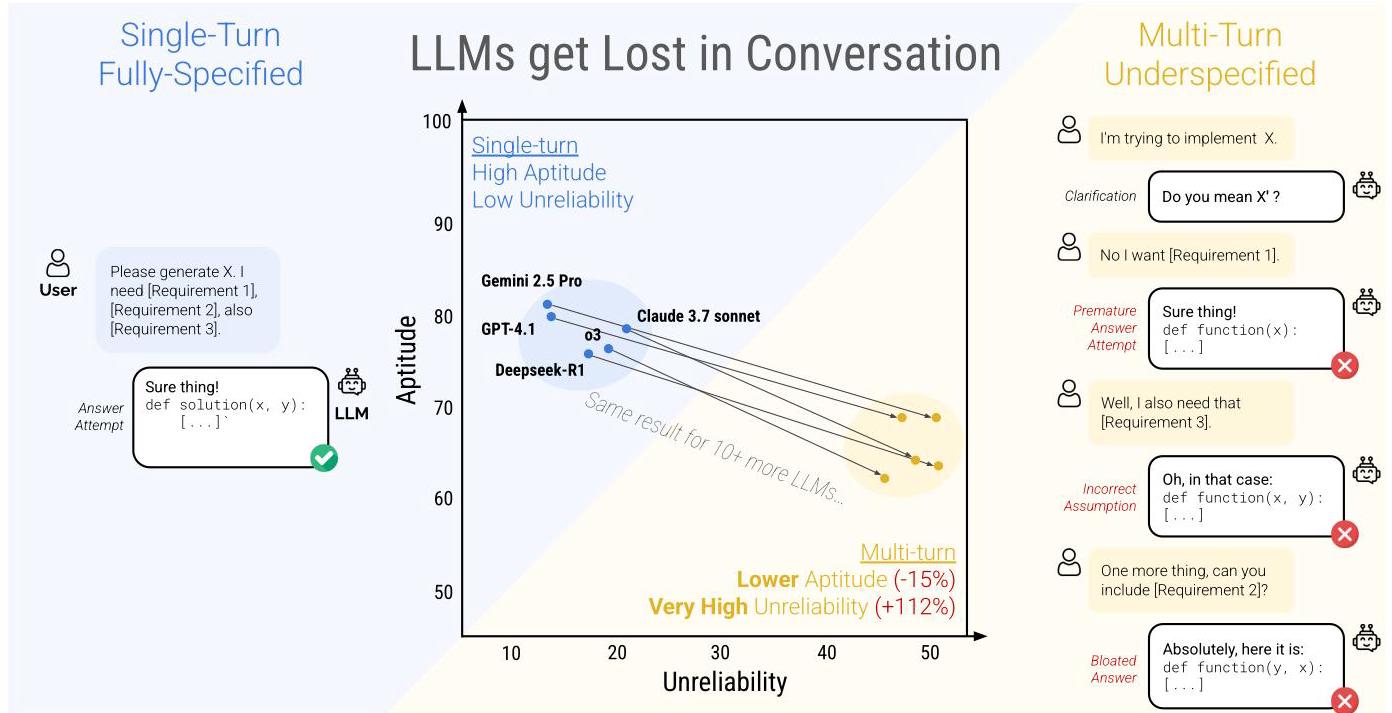
所有被测模型在多轮对话中性能平均下降 39%
(P̄)
(A90)
(U1090)
退化不是能力不足(Aptitude 仅降 16%),而是可靠性崩塌(Unreliability 翻倍)。模型不是“不会做”,而是“有时做对有时做错”。
核心方法:指令分片
将完整单轮指令拆分为原子化的 shard,模拟用户逐步说清需求的过程。
Jay is making snowballs to prepare for a snowball fight with his sister. He can build 20 snowballs in an hour, but 2 melt every 15 minutes. How long will it take before he has 60 snowballs?
Shard 1: How long before Jay's ready for the snowball fight?
Shard 2: He's preparing for a fight with his sister.
Shard 3: He can make 20 snowballs per hour.
Shard 4: He's trying to get to 60 total.
Shard 5: 2 melt every 15 minutes.
半自动分片流程
模拟环境与五种设定
持有全部 shard,每轮选择最合适的一个揭示给 assistant
判断助手回复是否包含 answer attempt——只有 answer attempt 才触发评分,其他类型(澄清、讨论等)继续对话
从自由文本中提取可评估的答案(代码/SQL/数值),送入任务评测器
| 模拟类型 | 轮次 | 信息揭示 | 目的 |
|---|---|---|---|
| FULL | 单轮 | 原始完整指令 | 基线 |
| CONCAT | 单轮 | 全部 shard 拼接 | 排除改写因素 |
| SHARDED | 多轮 | 每轮最多 1 个 shard | 主实验 |
| RECAP | 多轮+末轮复述 | 同 SHARDED + 末轮全复述 | 缓解策略 |
| SNOWBALL | 多轮+逐轮累积 | 每轮新 shard + 重述旧 shard | 缓解策略 |
6 个生成任务
覆盖编程(Code, Database, Actions)和自然语言(Math, Data-to-text, Summary)两大类,每个任务 90–120 条分片指令,共 600 条。

主结果:15 个模型全面退化
| Model | P̄ (FULL) | P̄ (CONCAT) | P̄ (SHARDED) | 多轮退化幅度 |
|---|---|---|---|---|
| Gemini 2.5 Pro | 95.0 | 95.1 | 61.2 | ↓ 35.5% |
| GPT-4.1 | 93.8 | 91.9 | 58.0 | ↓ 38.2% |
| Claude 3.7 Sonnet | 90.8 | 91.2 | 59.8 | ↓ 34.1% |
| o3 (reasoning) | 89.4 | 87.7 | 57.3 | ↓ 35.9% |
| DeepSeek-R1 (reasoning) | 87.9 | 91.1 | 53.4 | ↓ 39.2% |
| GPT-4o | 88.2 | 83.4 | 51.1 | ↓ 42.1% |
| Llama 3.3-70B | 85.6 | 79.7 | 55.0 | ↓ 35.8% |
| Llama 3.1-8B | 53.7 | 49.2 | 33.6 | ↓ 37.5% |
CONCAT ≈ FULL(平均保持 95.1%)→ 分片改写不丢失信息。SHARDED 的退化完全来自多轮欠规约本身。推理模型(o3, R1)同样退化 35–39%,额外 thinking tokens 无法解决多轮问题。
Aptitude vs. Reliability
更强的模型更可靠
Aptitude ↑ ⇒ Unreliability ↓
GPT-4.1 和 Gemini 2.5 Pro 同时拥有最高 aptitude 和最低 unreliability。
所有模型同样不可靠
Aptitude 仅降 16%
Unreliability 飙升 112%
最佳与最差模拟的差距平均达 ~50 分。模型能力还在,但输出质量高度不稳定。
P̄ 的大幅下降主要归因于 Unreliability 的飙升,而非 Aptitude 的下降。模型不是"不会做",而是"有时做对有时做错"——走错一步就再也回不来。
两轮就够,降温无效
固定任务难度,仅变分片粒度(2–8 shards)。
从 2-shard(两轮)开始,退化就已触发。
更多 shard 不会显著加剧退化。
一次性提供所有信息是唯一有效的可靠性保障。
单轮:T=0 降 Unreliability 50–80%
多轮:即使 T=0(assistant + user 都为 0),仍残留 U ≈ 30%
早期一个 token 的偏差在多轮中级联放大,温度无法控制这种结构性不稳定。
四个根因
四个根因共同指向一个结论:模型被自己早期生成的(错误)输出所锚定,无法根据后续新信息自我纠正。
论文的缓解尝试
| Model | FULL | SHARDED | RECAP | SNOWBALL |
|---|---|---|---|---|
| GPT-4o-mini | 86.8 | 50.4 | 66.5 | 61.8 |
| GPT-4o | 93.0 | 59.1 | 76.6 | 65.3 |
论文对用户的终极建议:“重开对话” — 让 LLM 先整合信息,再带到新对话中。Cursor 社区经验证实了这一策略。
三个结论
学术影响力分析
基于 Google Scholar 引用数据的数据驱动分析
引用增长与发布平台
46% 引用论文自身零被引 → 大量全新工作仍在涌入
引用论文分类
FiC, MAIGO, RLAAR, CCOPD, Memory-Aug RL, RLSTA
推理时 10 篇
ERGO, D-SMART, Mt-osc, Rhea, SeDT, SOMA, Context-agent, Context Branching, Intent Mismatch, Cognitive Fixation
16 篇直接竞品的方法路线
自蒸馏:FiC, MAIGO, CCOPD
共同思路:修改模型权重,让模型学会在多轮中保持一致性。需要训练数据、GPU 时间,且绑定特定模型。
结构化记忆:D-SMART(知识图谱), Rhea(episodic memory)
压缩/凝缩:Mt-osc, SOMA, Cognitive Fixation
加权/条件化:SeDT(return-to-go 加权), Intent Mismatch
分支管理:Context-agent, Context Branching
不改模型权重,模型无关。但切入角度各异——
10 篇推理时方法的共同特点:要么无差别压缩整个历史(Mt-osc, SOMA),要么全量重置(ERGO),要么加权保留(SeDT, Rhea)——都是在决定"保留什么"。
没有一篇反过来问:应该主动丢弃什么? 被取代的旧方案、已完成的中间过程、被否决的探索路径——这些内容是否应该从上下文中移除?
竞争方法分析
16 篇直接竞品的方法维度对比
训练时方法对比
| 方法 | 核心机制 | 对有害上下文的策略 | 训练开销 | LiC 结果 |
|---|---|---|---|---|
| FiC | 视图不对称自蒸馏 | 训练模型免疫 | SFT + VASD(全参) | 恢复 92–100% |
| MAIGO | 历史清洗 + 在线蒸馏 | 训练模型免疫 | On-policy distill | 52.8→66.1 |
| CCOPD | 冻结教师 + reverse KL | 训练模型免疫 | LoRA 0.53% 参数 | +32% |
| RLSTA | RL + 单轮锚点奖励 | 训练模型免疫 | RL 训练 | 0.652→0.784 |
| RLAAR | RL + 弃权奖励 | 训练模型拒答 | 课程 RL | 62.6→75.1% |
| Mem-RL | 256-token 滚动缓冲 + DAPO | 隐式丢弃(固定窗口) | RL 训练 | memory > full-hist |
共同特点:全部选择修改模型权重,不改变上下文内容。有害信息仍留在上下文中,模型被训练去"抵抗"它。需要训练数据和 GPU 时间,且绑定特定模型。
FiC — Found in Conversation
Chen, Wu, Leskovec · Stanford University · arXiv 2026
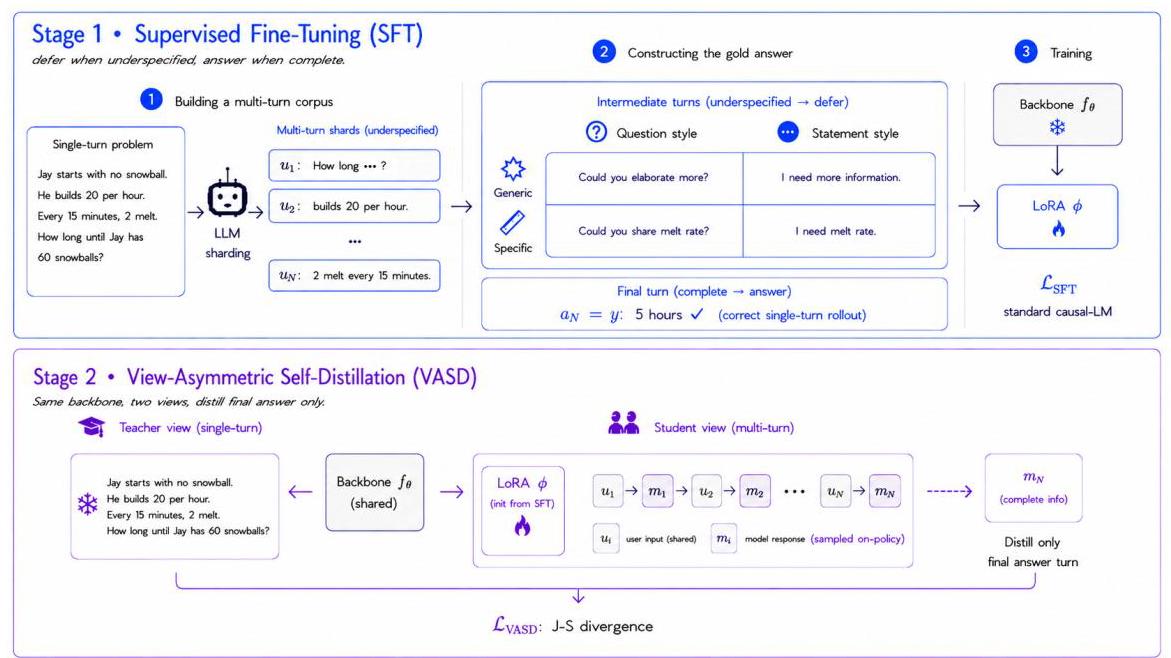
View-Asymmetric Self-Distillation:用模型自身单轮表现作教师,教导多轮表现。先 SFT 学会 defer,再 VASD 关闭 gap。恢复 92–100% 单轮性能。
关键声明:论文测试了 4 种推理时干预(system prompt engineering, history summarization, self-reflection, one-shot demonstration)并声称全部失败。这是对推理时方法方向的直接挑战——但这 4 种都是"不改上下文内容"的软干预,而非物理移除。
MAIGO — Self-Contamination 诊断
Zheng et al. · Zhejiang University / Shanghai AI Lab / Tencent · arXiv 2026
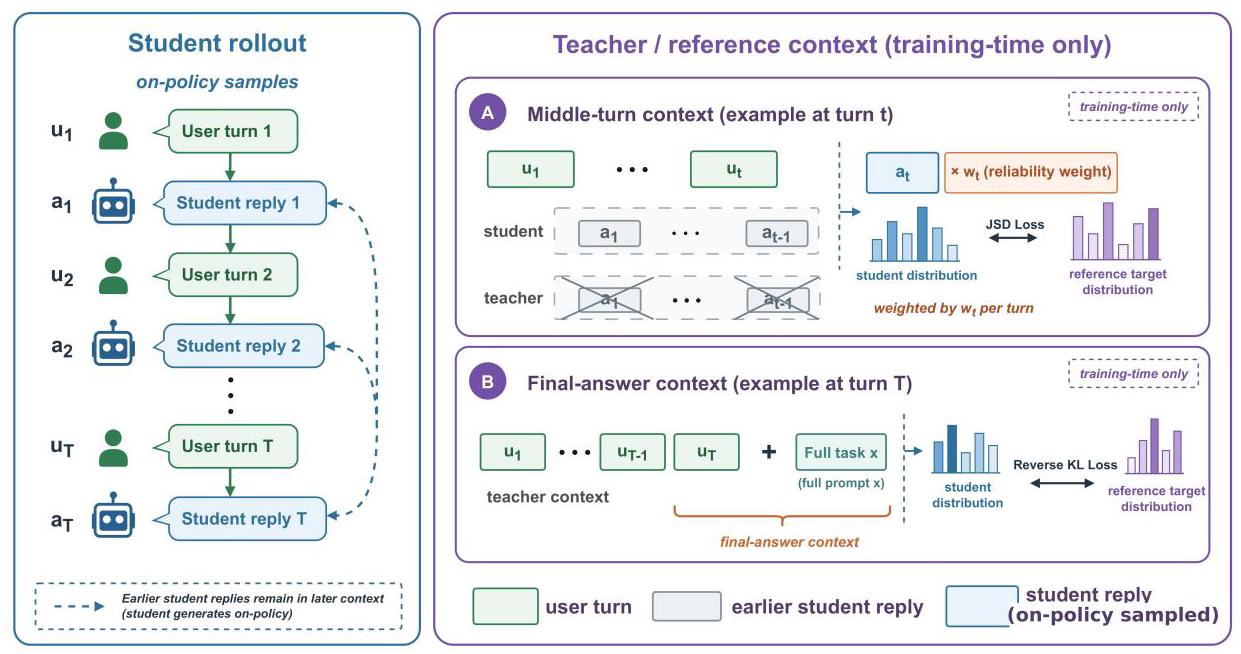
诊断 self-contamination:中间轮 assistant 回复携带早期偏差进入后续上下文。用 history-cleaned reference 做 on-policy self-distillation。Qwen2.5-7B SHARDED 52.8 → 66.1。
值得注意:MAIGO 的 “self-contamination” 与 Lost in Conversation 的根因分析高度一致。对根因的诊断趋同,分歧在治疗路线:训练模型去抵抗污染,还是直接移除污染源?
推理时方法对比
| 方法 | 核心操作 | 对有害上下文的策略 | 粒度 | 额外调用 | LiC | 代表结果 |
|---|---|---|---|---|---|---|
| ERGO | entropy 触发全量重构 | 全量移除(重构) | 全局 | 1 次重生成 | ✓ | +56.6% |
| Cog. Fixation | 自我疏离 + 孵化 | 全量替代(摘要替换) | turn 级 | 1–2 次 | ✓ | 恢复 85–86% |
| MT-OSC | 异步渐进压缩 | 压缩保留 | turn 级 | condenser | ✗ | token −72% |
| Rhea | 双记忆分层 + 检索 | 压缩保留 | episode 级 | LoRA 推理 | ✗ | +16.4% |
| Context-Agent | 动态话题树 | 非活跃路径压缩 | episode 级 | 分类器 | ✗ | token −45–52% |
| SeDT | return-to-go 加权 | 加权保留(全部留着) | shard 级 | 无 | ✓ | 最高 +37.7% |
| Intent Mismatch | Mediator 重写指令 | 不处理上下文 | turn 级 | 1 次 | ✓ | ~20% 恢复 |
| D-SMART | 知识图谱 + 推理树 | 结构化存储替代 | 实体级 | 多次 | ✗ | DER +48–84% |
| SOMA | 小模型局部近似 | 不处理(切换模型) | session 级 | 无 | ✗ | token −37% |
| ContextBranch | 版本控制分支隔离 | 分支隔离(不删除) | branch 级 | 无 | ✗ | +2.5% |
ERGO — 全量重构策略
Khalid et al. · Algoverse AI Research · 2025
每轮计算输出 token 的平均 Shannon entropy H̄,跟踪相邻轮次的变化 ΔH̄。超过阈值 τ 时触发全量 prompt 重构——合并所有用户输入为单轮重新生成。平均提升 56.6%。
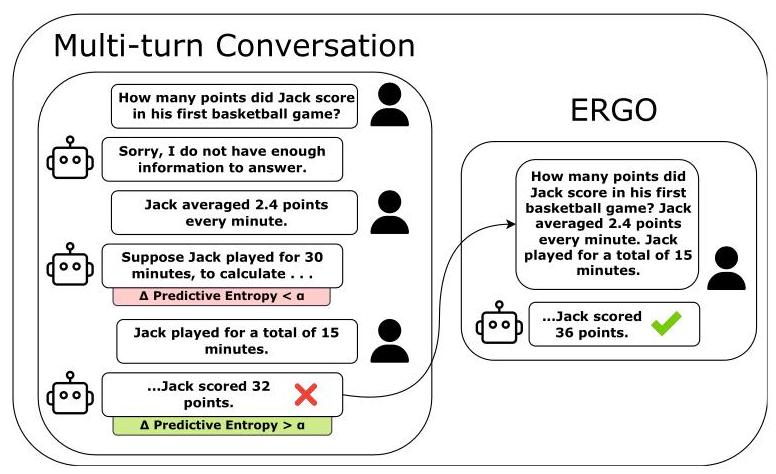
强 → 宽松
弱 → 敏感
特点与局限:一旦触发,丢弃全部对话历史重新生成。有效但粗粒度——有用的中间信息和教训也一并丢失。
Cognitive Fixation — 认知心理学视角
Gwon et al. · ETRI, South Korea · ICASSP 2026
动机来自认知心理学:人在解决问题时会被最初想到的方案“锁死”,即使它是错的也难以跳出——这叫认知固着(cognitive fixation)。作者认为 LLM 在多轮对话中的表现与此一致:早期给出错误答案后就被锚定,后续无法纠正。
借鉴心理学中治疗认知固着的两种方法:
心理学:换第三方视角审视自己的想法,打破自我锚定。
LLM 实现:让模型以第三人称旁观者角色审视对话中助手的回答,指出错误并重新作答。从“辩护者”变成“批评者”。
心理学:遇到难题暂时放下,做别的事再回来,反而更易解决。
LLM 实现:将对话中所有助手回复替换为一句话摘要,让模型“远离”自己之前的详细回答,基于清理后的上下文重新生成。恢复至单轮的 85–86%。
局限:Incubation 是无差别替代所有助手回复——不区分有害/有用,不区分回复的角色和质量,且摘要只记录"讨论了什么",不保留"为什么失败了"的判断。
竞争定位:一个尚未被占据的位置
Just Forget
选择性遗忘作为多轮对话退化的解药
三条独立证据链汇聚到同一个结论
被取代的信息留在上下文里就是毒,模型架构上没有"忽略"的能力——唯一出路是从上下文中物理移除。
方法设计
把每个对话轮次当作节点,构建基于节点的遗忘机制。
三种遗忘类型
对应根因:Premature Answering + Answer Bloat
对应问题:已完成阶段的过程残留
对应根因:Over-verbosity
两个关键设计
遗忘后不留摘要,留判决——"尝试了 X,因 Y 失败,勿重试"。一句话负知识:丢掉污染,保留教训。
激进遗忘助手节点(污染源),保守保留用户节点(规格说明)。正反馈:遗忘使上下文变短 → lost-in-the-middle 效应减弱。
示例:三种遗忘的组合与嵌套
场景:用 AI 助手调试 LoRA 微调脚本
墓碑:“lr 调整未解决 loss 问题”
墓碑:“cosine sched 后被优化版取代”
墓碑:“全参微调,显存不足放弃”
结论:“LoRA + ckpt + bf16,见 train.py”
1 行结论 + 当前问题
三个贡献
实验设计
使用原论文 6 个任务、sharded 指令、P̄ / A90 / U1090 指标。实施取代性遗忘,目标:unreliability 恢复显著超过 SNOWBALL 的 15-20%。
子目标或任务完成后继续对话。三种干扰条件:不相关 / 表面相似 / 确实相关。测试情节性遗忘(保留结论,遗忘过程)的效果。
消融矩阵
| 条件 | 删了什么 | Token 预算 |
|---|---|---|
| Just Forget | 被取代的 attempts + 死路 | ~K |
| 随机遗忘 | 随机等量内容 | ~K(配平) |
| FIFO | 最早的内容 | ~K(配平) |
| Auto-compact | 全局摘要 | 约等效压缩比 |
| SNOWBALL | 不删(加法) | 0(增加) |
| 无干预 | 不删 | 0 |
| 新对话 | 全删 | 全部 |
预期结论
Token 预算相同,但定向遗忘远优于随机 → 收益来自移除有害内容,而非缩短上下文。
压缩保留了错误信息的精华,遗忘直接移除污染源 → 范式性的差异。
新对话是全量遗忘(上界),Just Forget 以最小信息损失达到接近效果。
What to forget matters more than how much to forget.
Thank You
2026/06/22 · Runqing Xu